In today’s world of information overload, teams need smarter ways to access knowledge buried in long documents, reports, and manuals. What if you could upload a PDF, ask natural questions like “What’s the warranty policy?” or “Summarise section 3.2,” and get instant, accurate answers powered by AI?
Page Contents
That’s exactly what you’ll learn today: how to create a Q&A system from PDFs using embeddings and vector databases such as Pinecone, FAISS, or Chroma.
By the end of this guide, you’ll have your own intelligent assistant that understands your documents, not just the internet.
What’s the Idea Behind PDF Q&A Systems?
Before diving into code, let’s break it down simply.
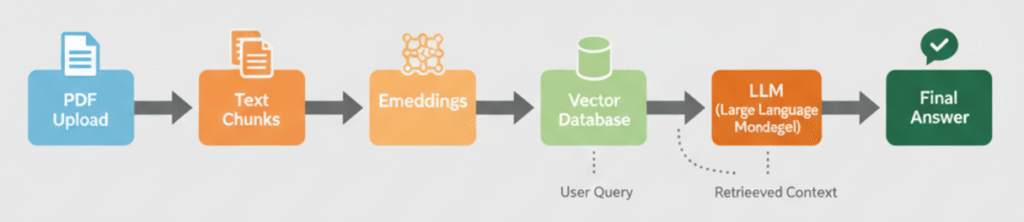
When you upload a document and ask a question, the system performs three main steps:
- Split the document into chunks (since LLMs can’t process huge files directly).
- Convert each chunk into embeddings — numerical representations of meaning.
- Store these embeddings in a vector database, where the system can find the most relevant chunks later.
Then, when a user asks a question:
- The system retrieves the most relevant chunks (via similarity search).
- The LLM reads them and generates a natural, contextual answer.
That’s the magic of Retrieval-Augmented Generation (RAG) applied to PDFs.
Tech Stack Overview
Here’s what we’ll use:
- LangChain – to handle document loading, splitting, and chaining LLMs.
- OpenAI Embeddings – to convert text into meaningful vectors.
- Pinecone / FAISS / Chroma – as our vector database.
- Streamlit (optional) – for a simple chat-like user interface.
Step 1. Project Setup
Make sure you have Python 3.9+ and install the required dependencies:
pip install langchain openai pinecone-client tiktoken pypdf streamlit
Create a .env file to store your API keys:
OPENAI_API_KEY=your-openai-key
PINECONE_API_KEY=your-pinecone-key
PINECONE_ENV=us-west1-gcp
Then, load them in your Python script:
from dotenv import load_dotenv
load_dotenv()
Step 2. Extract Text from PDFs
LangChain provides an easy way to read and split large PDF documents:
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = PyPDFLoader("company_policy.pdf")
documents = loader.load()
# Split into smaller text chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
docs = text_splitter.split_documents(documents)
This ensures that your document is broken into manageable parts for embedding.
Step 3. Create and Store Embeddings
Now, we’ll convert text chunks into embeddings and store them in a vector database.
Here’s how you can do it using Pinecone:
import pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
# Initialize Pinecone
pinecone.init(api_key=os.getenv("PINECONE_API_KEY"), environment=os.getenv("PINECONE_ENV"))
index_name = "pdf-qa-system"
if index_name not in pinecone.list_indexes():
pinecone.create_index(index_name, dimension=1536)
embeddings = OpenAIEmbeddings()
vector_store = Pinecone.from_documents(docs, embeddings, index_name=index_name)
Alternatively, if you want a local setup, use FAISS or Chroma instead of Pinecone.
Step 4. Build the Q&A Chain
We’ll now connect our retriever to the LLM to form the complete Q&A chain.
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
llm = ChatOpenAI(temperature=0)
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
This chain takes user input, retrieves relevant PDF chunks, and generates an answer.
Step 5. Ask Questions from Your PDF
Now, test your system:
query = "What is our company’s leave policy?"
response = qa_chain({"query": query})
print(response["result"])
The system will return the answer based on your uploaded document, even if it’s 200 pages long.
Step 6. (Optional) Add a Simple Chat UI
To make it interactive, use Streamlit:
pip install streamlit
import streamlit as st
st.title("📘 PDF Q&A Assistant")
query = st.text_input("Ask something from your document:")
if query:
result = qa_chain({"query": query})
st.write(result["result"])
Run the app:
streamlit run app.py
You now have a fully functional PDF Q&A assistant that feels like ChatGPT, but for your documents.
Step 7. Optimise and Scale
To make your system production-ready:
- Use embedding caching to speed up retrieval.
- Implement chunk overlap tuning for context preservation.
- Integrate document re-upload and indexing pipelines.
- Add source highlighting (show which pages the answers came from).
These improvements help your Q&A system handle real-world enterprise data efficiently.
Final Thoughts
You’ve just built a Q&A system powered by embeddings and vector databases, a foundational pattern behind modern enterprise AI. From HR manuals to research papers, you can now turn any static PDF into a living, searchable knowledge assistant.
With just a few steps, you’ve transformed documents into something truly interactive, an AI that reads, remembers, and responds intelligently.
Recommended Resources

Parvesh Sandila is a results-driven tech professional with 8+ years of experience in web and mobile development, leadership, and emerging technologies.
After completing his Master’s in Computer Applications (MCA), he began his journey as a programming mentor, guiding 100+ students and helping them build strong foundations in coding. In 2019, he founded Owlbuddy.com, a platform dedicated to providing free, high-quality programming tutorials for aspiring developers.
He then transitioned into a full-time programmer, where his hands-on expertise and problem-solving skills led him to grow into a Team Lead and Technical Project Manager, successfully delivering scalable web and mobile solutions. Today, he works with advanced technologies such as AI systems, RAG architectures, and modern digital solutions, while also collaborating through a strategic partnership with Technobae (UK) to build next-generation products.