In 2025, building smart, context-aware AI assistants is no longer a luxury. It’s the new norm. Whether you’re developing a customer support bot, an internal knowledge assistant, or a personalised learning companion, Retrieval-Augmented Generation (RAG) offers the perfect way to combine the power of Large Language Models (LLMs) with your private data.
Page Contents
In this guide, you’ll learn how to build a RAG Chat Assistant using LangChain and Pinecone, from concept to deployment. By the end, you’ll have a working AI assistant that can answer questions based on your own documents, not just what it was trained on.
What Is Retrieval-Augmented Generation (RAG)?
Before diving into the code, let’s understand the idea behind RAG.
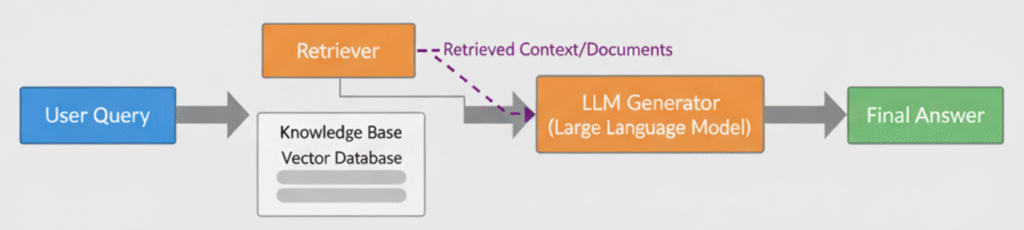
RAG combines two main steps:
- Retrieval – Searching your private data for the most relevant pieces of information.
- Generation – Feeding that information to an LLM (like GPT-4 or Claude) to create accurate, context-rich answers.
This means your assistant doesn’t rely purely on pre-trained model knowledge. It retrieves facts dynamically from your own dataset.
Why Use LangChain + Pinecone?
- LangChain helps you build modular AI pipelines that combine retrieval, prompt engineering, and LLM reasoning.
- Pinecone is a vector database optimised for similarity search, perfect for storing and retrieving embeddings efficiently.
Together, they form the foundation of scalable, production-ready RAG systems.
Project Setup
Prerequisites
Make sure you have:
- Python 3.9+
- An OpenAI (or Anthropic) API key
- A Pinecone account
- Basic understanding of Python and APIs
Step 1. Install Dependencies
pip install langchain openai pinecone-client tiktoken
Step 2. Initialise Environment Variables
Create a .env file with your credentials:
OPENAI_API_KEY=your-openai-key
PINECONE_API_KEY=your-pinecone-key
PINECONE_ENV=us-west1-gcp
Then, load them in your script:
from dotenv import load_dotenv
load_dotenv()
Step 3. Create Embeddings and Store Them in Pinecone
Embeddings convert text into numeric vectors that represent meaning. You’ll use these vectors to perform a semantic search.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
import pinecone
# Initialize Pinecone
pinecone.init(api_key=os.getenv("PINECONE_API_KEY"), environment=os.getenv("PINECONE_ENV"))
# Create index
index_name = "rag-chatbot"
if index_name not in pinecone.list_indexes():
pinecone.create_index(index_name, dimension=1536)
# Initialize embeddings and store documents
embeddings = OpenAIEmbeddings()
docsearch = Pinecone.from_texts(
["Your company FAQs", "Internal policy document", "Knowledge base article"],
embeddings,
index_name=index_name
)
Step 4. Build the RAG Chat Pipeline
Now you’ll connect the retriever and the LLM into a LangChain pipeline.
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Initialize model
llm = ChatOpenAI(temperature=0)
# Create retriever from Pinecone index
retriever = docsearch.as_retriever(search_kwargs={"k": 3})
# Combine retriever and LLM
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
Now your assistant can pull the most relevant information before generating an answer.
Step 5. Chat Interface Example
Here’s how you can interact with your assistant:
query = "What is our refund policy?"
result = qa_chain({"query": query})
print(result["result"])
You’ll get a personalised, context-aware response based on your stored documents.
Step 6. (Optional) Build a Simple Web UI
You can quickly integrate this backend with Streamlit or Flask to create a chat interface.
Example with Streamlit:
pip install streamlit
import streamlit as st
st.title("RAG Chat Assistant 💬")
query = st.text_input("Ask your question:")
if query:
result = qa_chain({"query": query})
st.write(result["result"])
Step 7. Evaluate and Improve
Your RAG assistant is only as good as its data. To improve:
- Add more relevant documents.
- Experiment with embedding models.
- Adjust
k(retrieval depth) for a balance between speed and accuracy. - Use feedback loops to fine-tune responses.
Final Thoughts
You’ve just built a Retrieval-Augmented Generation Chat Assistant using LangChain and Pinecone, a powerful combination for building AI tools that “know what you know.” This same approach powers knowledge bots, AI copilots, and enterprise search assistants used by top tech companies today.
With just a few steps, you’ve taken your first stride toward custom AI assistants that actually understand your business context.
Bonus Resources

Parvesh Sandila is a results-driven tech professional with 8+ years of experience in web and mobile development, leadership, and emerging technologies.
After completing his Master’s in Computer Applications (MCA), he began his journey as a programming mentor, guiding 100+ students and helping them build strong foundations in coding. In 2019, he founded Owlbuddy.com, a platform dedicated to providing free, high-quality programming tutorials for aspiring developers.
He then transitioned into a full-time programmer, where his hands-on expertise and problem-solving skills led him to grow into a Team Lead and Technical Project Manager, successfully delivering scalable web and mobile solutions. Today, he works with advanced technologies such as AI systems, RAG architectures, and modern digital solutions, while also collaborating through a strategic partnership with Technobae (UK) to build next-generation products.