Artificial Intelligence is rapidly evolving beyond words. It now sees, listens, and understands context like never before. This evolution has given rise to multimodal AI, systems that combine multiple input types (like text, images, and audio) to deliver human-like understanding.
Page Contents
In this detailed guide, we’ll build a multimodal AI app capable of generating image captions and answering follow-up questions about the same image, just like ChatGPT’s vision mode or Gemini’s multimodal capabilities.
Whether you’re a developer, a startup founder, or an AI enthusiast, by the end of this tutorial, you’ll understand how to connect vision models with language models to create smart, interactive AI products.
What Is a Multimodal App?
A multimodal app is an AI system that processes and understands different types of data, for example, images, text, and audio, in a unified way. Unlike traditional text-only LLMs, multimodal systems can “see” and “describe” what’s in an image, and even carry a meaningful conversation about it.
Example Scenario:
You upload an image of a dog sitting in a park.
The model generates a caption like:
“A golden retriever sitting on green grass in a sunny park.”
Then you ask:
“What season does it look like?”
The model replies:
“It looks like spring or early summer due to the bright sunlight and green trees.”
That’s the power of multimodal intelligence, blending visual and textual understanding seamlessly.
Why Multimodal AI Matters in 2025
In 2025, multimodal AI isn’t just a novelty. It’s a competitive advantage. Companies are now embedding these capabilities into search engines, social apps, healthcare, e-commerce, and education.
Some real-world use cases:
- Search & Recommendation – “Find items similar to this image.”
- Accessibility – Describe scenes for visually impaired users.
- Document Analysis – Read charts or images from PDFs.
- Creative Tools – Caption and describe artwork for metadata.
- Chatbots – Answer contextual questions about images (e.g., customer support or product queries).
Building even a basic multimodal prototype gives you an edge in understanding the next generation of AI-powered interfaces.
Tech Stack Overview
We’ll use the following tools for this tutorial:
| Tool | Purpose |
|---|---|
| Python | Core programming language |
| OpenAI GPT-4 Vision / Gemini / Claude 3 | Multimodal model for image + text understanding |
| Gradio | Simple web-based user interface |
| Pillow (PIL) | Image processing |
| Optional: FastAPI | To deploy as an API for production apps |
Architecture Overview
Our multimodal app will follow this workflow:
User uploads an image → Model generates a caption → User asks questions → Model analyses the image again and responds based on visual + textual context.
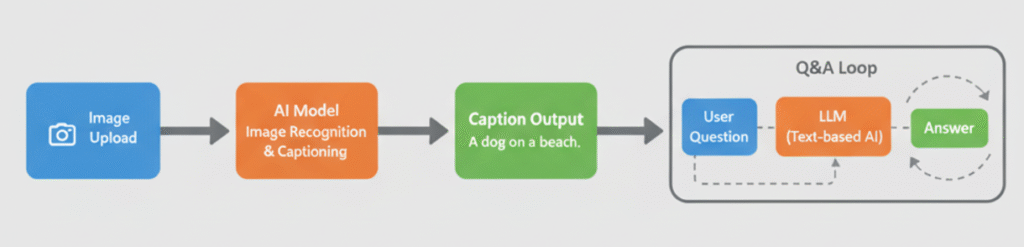
Step 1: Environment Setup
Start by installing the required dependencies.
pip install openai pillow gradio
Then, import them into your Python file.
import openai
from PIL import Image
import gradio as gr
Set your API key:
openai.api_key = "YOUR_API_KEY"
Step 2: Generate an Image Caption
The first part of the app generates a caption from an uploaded image using GPT-4 Vision or any similar multimodal model.
def generate_caption(image_path):
with open(image_path, "rb") as img:
response = openai.ChatCompletion.create(
model="gpt-4-vision-preview",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "Describe this image in detail."},
{"type": "image_url", "image_url": image_path}
]}
],
max_tokens=150
)
return response.choices[0].message["content"]
Explanation:
- The model analyses the image.
- It returns a natural-language description summarising the visual context.
Step 3: Enable Follow-Up Q&A
Now, let’s add the ability to ask questions about the same image. The key is to pass both the image and the question in the same request.
def ask_question(image_path, question):
with open(image_path, "rb") as img:
response = openai.ChatCompletion.create(
model="gpt-4-vision-preview",
messages=[
{"role": "user", "content": [
{"type": "text", "text": question},
{"type": "image_url", "image_url": image_path}
]}
],
max_tokens=200
)
return response.choices[0].message["content"]
Example:
- Caption: “A person riding a mountain bike through a forest trail.”
- Question: “Is the person wearing a helmet?”
- Answer: “Yes, they’re wearing a black helmet.”
This simple logic forms the core of a vision-language reasoning system.
Step 4: Build an Interactive UI with Gradio
Let’s bring it all together in a clean, no-code interface using Gradio.
def multimodal_app(image, question):
if not question:
return generate_caption(image)
else:
return ask_question(image, question)
iface = gr.Interface(
fn=multimodal_app,
inputs=[gr.Image(type="filepath"), gr.Textbox(label="Ask a question (optional)")],
outputs="text",
title="Multimodal App: Image Captioning + Q&A",
description="Upload an image and either get a caption or ask follow-up questions."
)
iface.launch()
Once you run the script, Gradio opens a local web interface.
You can:
- Upload an image
- Generate its caption
- Type a question like “What’s happening in the background?”
Step 5: Add Context Memory (Optional)
If you want the model to remember previous questions and answers, store conversation history:
history = []
def ask_with_memory(image_path, question):
with open(image_path, "rb") as img:
history.append({"type": "text", "text": question})
history.append({"type": "image_url", "image_url": image_path})
response = openai.ChatCompletion.create(
model="gpt-4-vision-preview",
messages=[{"role": "user", "content": history}],
max_tokens=250
)
answer = response.choices[0].message["content"]
history.append({"type": "text", "text": answer})
return answer
This enables a multi-turn conversation about one image.
Step 6: Expanding to Full Multimodal Apps
You can extend this prototype into production-grade tools such as:
- Medical Assistants: Analyse X-rays or scans and answer diagnostic questions.
- E-commerce: Let users upload product images and get automatic descriptions or related item suggestions.
- Document Analysis: Read and interpret graphs, charts, or invoices.
- Education: Students upload diagrams and ask concept-related questions.
Challenges to Consider
- API costs: Vision models can be expensive for large-scale usage.
- Latency: Image processing is heavier than text requests.
- Data privacy: Avoid uploading sensitive images to third-party APIs.
- Bias in models: AI interpretations may vary depending on dataset exposure.
Always include disclaimers for real-world usage.
Conclusion
You’ve just built a working multimodal AI app that can both describe and reason about images, combining computer vision and language models into one intelligent system. This workflow is the foundation for next-generation products that understand the world the way we do — through multiple senses.
Whether you’re building visual assistants, smart document readers, or AI search systems, multimodal integration will be at the core of the next wave of innovation.
Now, it’s your turn to take this base and make something extraordinary!

Parvesh Sandila is a results-driven tech professional with 8+ years of experience in web and mobile development, leadership, and emerging technologies.
After completing his Master’s in Computer Applications (MCA), he began his journey as a programming mentor, guiding 100+ students and helping them build strong foundations in coding. In 2019, he founded Owlbuddy.com, a platform dedicated to providing free, high-quality programming tutorials for aspiring developers.
He then transitioned into a full-time programmer, where his hands-on expertise and problem-solving skills led him to grow into a Team Lead and Technical Project Manager, successfully delivering scalable web and mobile solutions. Today, he works with advanced technologies such as AI systems, RAG architectures, and modern digital solutions, while also collaborating through a strategic partnership with Technobae (UK) to build next-generation products.